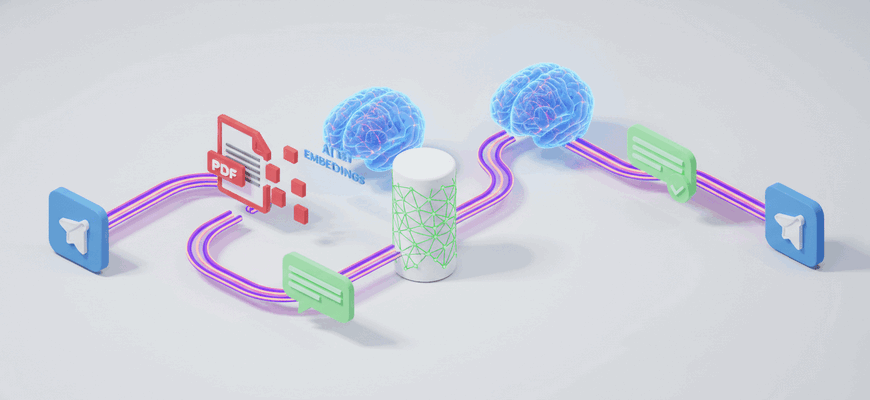
This workflow lets you upload a PDF via Telegram, index its content into a Pinecone vector store using OpenAI embeddings, and then chat with the document using a retrieval-augmented QA chain. It splits incoming PDF files into chunks, creates embeddings, stores them, and answers user questions by retrieving relevant chunks and sending responses back to the Telegram chat.
What You Can Do
- Receive PDF files in a Telegram chat and fetch the file automatically
- Normalize the incoming file metadata to ‘application/pdf’
- Split large documents into chunks with a recursive character text splitter
- Generate embeddings with OpenAI and insert vectors into a Pinecone index
- Retrieve relevant passages from Pinecone and answer user questions using a language model (Groq)
- Send status messages to the user when the PDF is indexed and return answers to chat queries
Quick Start
- Import this workflow into your n8n instance
- Configure credentials for Telegram, OpenAI, Pinecone and Groq in n8n (use placeholders like ‘YOUR_API_KEY’ if needed)
- Set up your Telegram bot webhook and ensure the workflow webhook path matches ‘/webhook/YOUR_WEBHOOK_ID’
- Activate the workflow, then send a PDF file to the Telegram bot to index it
- Ask questions in the same chat to retrieve information from the stored PDF content
